死活監視、リソース監視、運用監視ツール
システムを日々問題なく運用するのは容易ではありません。障害が発生しても早期に検知して対応する方法を紹介します。(LinuCレベル2 主題:2.04.5)
現在、WebサイトやSNS、サーバーと連携するスマホアプリなどインターネット上で提供されるサービスや、企業内のファイルサーバー、メールサーバー、グループウェアなどのシステムは、24時間365日いつでも問題なく使用できることが当然だと考えられています。
しかし、問題なくシステムを連続稼働させることは当然ではありません。それなりの対策が必要です。例えば、ハードウェア、ネットワーク、OSなど、システムを構成するさまざまな要素で障害が発生する可能性があるため、何らかの障害が発生してもシステム全体を停止せずに運用を継続させる仕組みが必要となります。
そのため、障害発生時のシステムやデータ復旧、サービス再稼働までの時間を短縮し、サービスのダウンタイムをできるだけ短くしてユーザーの利便性を損なわないためには、システムやサーバーを的確に監視してサービスが停止しないよう、障害をできるだけ早期に検知して対応することが重要です。
目次
システム障害と予兆
システムの障害を引き起こす原因には以下のようなものが考えられます。
- リソースの枯渇
メモリ消費量が実メモリ容量を超えてスワップ領域へのアクセスが多発すると、OSのパフォーマンスが大幅に落ちます。また、ディスク容量を使い果たしてしまうと、それ以上データを書き込んだりできなくなるためにシステムが停止してしまうトラブルが発生します。 - 過負荷
アプリケーションの処理などでCPU使用率が100%に達するとシステムが応答しなくなったり、アプリケーションの処理が遅延/停止して、ブラウザーやアプリへの応答がなくなり、処理結果が表示されない、などのトラブルを引き起こします。 - 異常停止
システム上のどこかで障害が発生した結果、システムやサービスが停止する場合があります。 - 結果異常
サービスが返す処理結果が異常な値を示していたり、データの破損により、システム障害が発生する可能性があります。 - OOMKiller
Linuxはメモリが不足(Out-Of-Memory:OOMと略す)してシステム停止が発生してしまう状況になると、メモリリソースを大量に消費しているプロセスを強制終了(kill)します。
停止処理をしていないプロセスが存在していない場合は、OSによって強制終了された可能性があります。Centosでは、/var/log/messages、Ubuntuなら/var/log/syslogの各OSのシステムログに、強制終了した情報が記録されます。
強制終了される可能性があるプロセスは、dstatコマンドのtop-oomオプションで確認できます。dstatコマンドは、/proc/PID/oom_scoreを参照して結果を表示します。
$ dstat --top-oom
--out-of-memory---
kill score
sshd 594
sshd 594
強制終了させるプロセスの優先度を設定しておくこともできます。
/proc/PID/oom_adjに、-16から+15までの優先度を設定することができます。 -17を設定すると強制終了の対象リストから外されます。
死活監視の対象と手法
死活監視の対象としては、
- サーバー
- ネットワーク機器
- サーバー上の特定のサービス
などがあります。
システムに対しての死活監視は、例えばサーバーのネットワークインターフェースに対して疎通確認を行い、応答(レスポンス)が返ってくるかどうかを確認します。
疎通確認が取れない場合には、サーバーが何らかの原因で停止しているか、ネットワークインターフェースに障害が発生しているなどのケースが考えられます。
また、各種サービスの死活監視については、Webサーバー、アプリケーションサーバー、メールサーバー、ファイルサーバーなどのプロセスが起動しているかを確認します。プロセスが起動していないとサービスが提供されません。また、CPUやメモリ、ディスクなどが不足するとサービスの提供に影響が出るので、次のリソース監視もあわせて実行します。
リソース監視の対象と手法
リソース監視の対象には、
- ログ(サーバー、サービス、プロセス、ネットワーク)
- 使用率(CPU、メモリ、ストレージ、通信量)
などがあります。
ログの監視
サーバーやネットワーク機器などのログファイルをtailコマンドなどを用いてコンソール上でリアルタイムに表示して確認することもできますが、ログ監視ツールや統合監視ツールなどを用いる方が管理者の負担が軽減できます。
ログ監視ツールを用いると、指定したディレクトリに保存されているログファイルをリアルタイムに監視して、特定のパターンにマッチしたら、メールでの通知を送信したり、スクリプトを実行することができます。
監視する対象としては、以下のようなログがあります。
- サーバーのシステムログ
- サービスごとのログファイル
例えば、httpdやnginxのログファイルにはサービスの起動、停止、エラーのログが記録されます。 - プロセスやネットワークの監視ログ
監視ツールから、定期的にプロセスの起動をチェックしたり、ネットワークの疎通確認を行った記録がログファイルに記録されます。
SNMPによるリソース監視
サーバーやネットワーク機器を監視するには、SNMP(Simple Network Management Protocol)を用いたリソース監視も使われます。これは、IPアドレスが設定されているさまざまなデバイスから情報を取得し、動作の状況や、障害の状況など、デバイスの状態を監視するための仕組みです。
監視対象としては、
- CPU、メモリ、ネットワークインターフェース、サーバー筐体の温度などの状態
- HDD、電源、ファンなどのハードウェアの稼働状況
- ネットワークの稼働状況(L2ループ、マルチキャストやブロードキャストパケットの多重ループ、が発生していないか)
などがあります。
また、監視には、
- SNMPマネージャからSNMPエージェントへのポーリング(定期的なリクエスト送信)
- SNMPエージェントからSNMPマネージャへの通知
の2タイプの仕組みがあります。
例えば、オープンソースの監視ツールであるNagiosにはSNMPマネージャの機能が内蔵されています。そして、監視対象のサーバーやデバイスではSNMPエージェントのプロセスが動作しています。SNMPマネージャは、SNMPエージェントに対して一定間隔(例えば3分おき)にリクエストの送信と、エージェントからのレスポンス受信を行います。
SNMPエージェントは、多くのルーターやスイッチなどのネットワークデバイスには組み込まれていることが多く、設定をすることで利用が可能になります。
Linuxでは、net-snmpパッケージにエージェントが含まれています。パッケージをインストールし、設定を行うことで利用が可能になります。
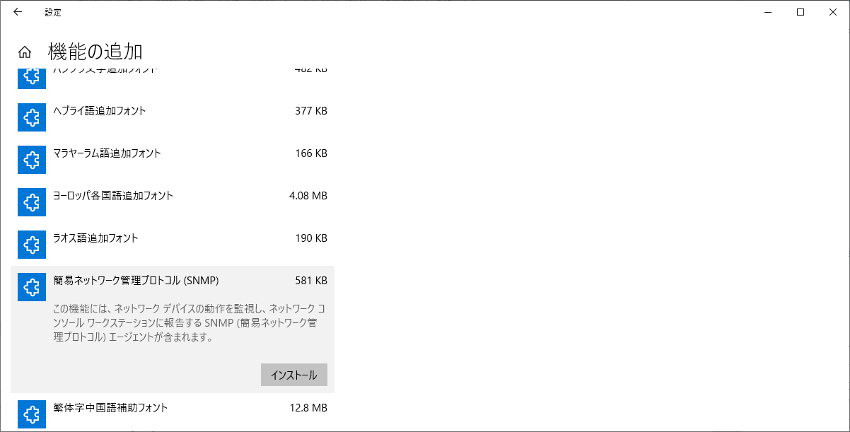
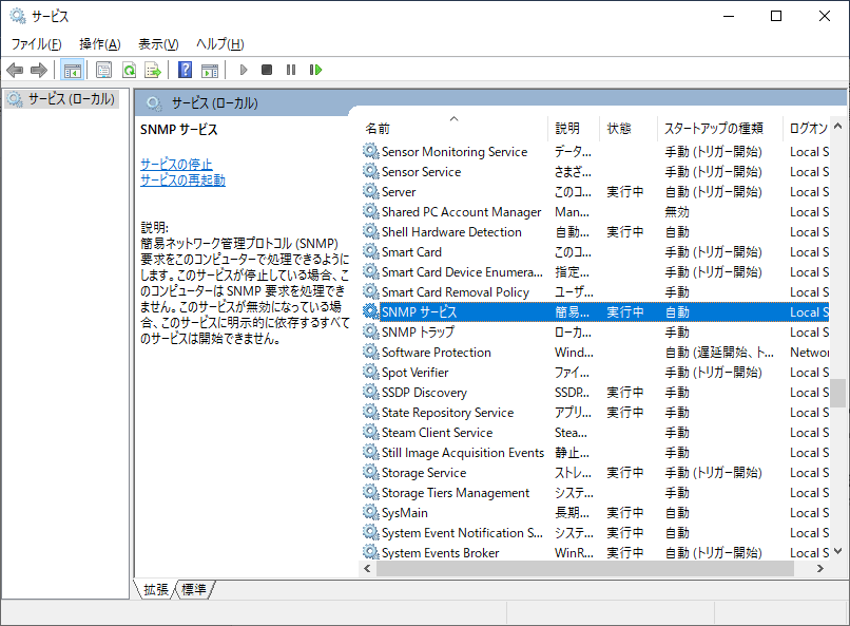
Windowsマシン[1]では「SNMP Service」を追加・設定して起動すればSNMPエージェントが使えるようになります。
アプリと機能の追加の設定メニューから「簡易ネットワーク管理プロトコル(SNMP)」を選択して、インストールを実行すると、サービスの一覧に表示されます。
運用監視ツールによる監視作業の標準化と自動化
サービスやデバイスごとに監視スクリプトを開発・実行し、ログ監視やリソース監視を手動で行うことはシステム規模が大きくなると負担が大きく、現実的ではありません。
そこで、監視ツールによる監視作業の標準化や自動化が重要になります。
例えば、オープンソースの監視ツールであるZabbixには以下のような監視、障害検知機能が搭載されています。
- ネットワーク上のノード監視
ICMP(ping)による死活監視 - リソース監視
CPU、メモリ、ディスク使用率 - ネットワークデバイス監視
監視ツールのエージェントプロセスやSNMPエージェントによる監視 - プロセス監視
ホスト上で動作しているプロセスの監視 - ポート監視
指定したポートを通じた通信が可能かどうかの監視 - サービス監視
HTTP, FTP, SMTP, POP, IMAP, LDAP, SSH, NNTP, NTPなどのサービスの動作監視 - ログ監視
ログファイル中に指定した文字列パターンが含まれないかを監視 - Windows監視
Windows用エージェントを使用するとWindowsのサービス起動状況やイベントログを監視できます。複数のエージェント対応、ソフトウェアのインストール・アンインストール、アプリケーションの起動・停止などWindows版固有の機能が搭載されています。
また、それぞれの項目についてしきい値を設定し、Eメールなどによるアラート通知方式を設定することが可能です。
監視方式の自動化やRBAによるパッケージ化
さらに、単一のノードの監視だけでなく、複数台のノードをまとめて監視したり、複数の処理を自動的に実行したりする自動化機能が備わっている監視ツールもあります。
こうした自動化機能は、RBA(Run Book Automation)と呼ばれ、問題や障害を検出した際にあらかじめ定義しておいた作業を自動的に実行することができるようになります。
監視業務の標準化の重要性
システム監視業務プロセスの改善にあたっては、既存の監視業務プロセスが効率的に行われているかどうかをチェックするところからスタートするとよいでしょう。
監視作業の自動化以前に、まず監視業務プロセス全体の見直しと標準化を行う必要があります。無駄な作業はないか、より効率を向上できないかなどをチェックしてから、監視プロセスの標準化を進めることが重要です。プロセスが標準化されれば、監視対象が増えても担当者の負担を軽減したり、作業ミスや運用の負担やコストを軽減したりすることにつながるでしょう。
標準化を進めることで監視ツールを統一したり、RBAによる自動化を適用したりしやすくなります。その結果、全体最適化を進めることが可能となるでしょう。
主要な監視ツール
Icinga2
Icinga2は、Nagios(後述)から派生(フォーク)して開発されたオープンソースの監視ツールです。Icinga2を用いるとWebインターフェース、もしくはコマンドラインインターフェースから監視設定を行うことができます。
標準的な監視機能(システムやリソースの監視、通知)に加えて、監視結果の可視化(動的なグラフ生成)や、分散構成への対応などの特徴があります。
Nagios
Nagiosもオープンソースの監視ツールの一つです。ネットワークサービスの監視、リソース監視、アラート機能など標準的な機能を備えています。基本的な設定はWebインターフェースから行います。
Nagiosはプラグインをユーザーが開発・追加できる点が特徴的です。Bash, C++, Perl, Ruby, Python, PHP, C#などで、監視したい対象についてプラグインを開発して使用することができます。
現在は、機能を強化した商用版と、オープンソース版が存在しています。新機能は商用版に主に追加されるため、Icingaのように分岐して新機能の開発を独自に進めるプロジェクトも出てきています。
collectd(https://collectd.org/)
collectdは、システムやアプリケーションのパフォーマンス情報を収集するオープンソースの監視ツールです。collectdは、100個以上の豊富なプラグインを使用して、システムやリソースの監視を行えます。収集したデータは、RRDというフォーマットで保存されます。
collectdはC言語で書かれているため、パフォーマンスが高く、実行ファイルのサイズが小さいのが大きな特徴です。そのため、一般的なサーバー以外にも組込み系システムやルーターなどにも搭載可能です。
一方で、グラフ生成機能は含まないため可視化ツールを併用する必要がある、モニタリング機能が限定的である、という短所もあります。
MRTG
MRTGは、「Multi Router Traffic Grapher」の略で、ルータなどネットワークデバイスが送受信したデータトラフィック量を可視化するために使用されるオープンソースの監視ツールです。
MRTGはPerl言語で書かれていて、取得した情報をHTML形式で出力可能なため、Webサーバーと連携して結果を表示させることができます。
もともとはルーターを監視対象として開発されましたが、現在はSNMPマネージャとして動作させることが可能で、SNMPエージェントと連携してサーバーやネットワークデバイスの監視が可能となっています。SNMPに対応しているため、ネットワークトラフィックだけでなく、サーバーのリソース状況(CPU、メモリ、ディスクなどの使用率)なども監視することが可能です。
欠点としては、二つの系列データの可視化までしかできないなど、可視化機能が弱い点が挙げられます。
Cacti
Cactiは、オープンソースの監視ツールの一つでSNMPマネージャとして機能することが可能です。
CactiはcollectdやMRTGが採用しているRRDフォーマットのデータを扱うことができるだけでなく、SNMP対応やWebインターフェースによる設定の容易さなどが特徴です。
CentOSでは、EPELリポジトリを追加するとyumコマンドでインストールすることが可能です。net-snmp, net-snmp-utilsの二つのパッケージをインストールすると、/etc/snmp/snmpd.confで設定を行うことができるようになります。
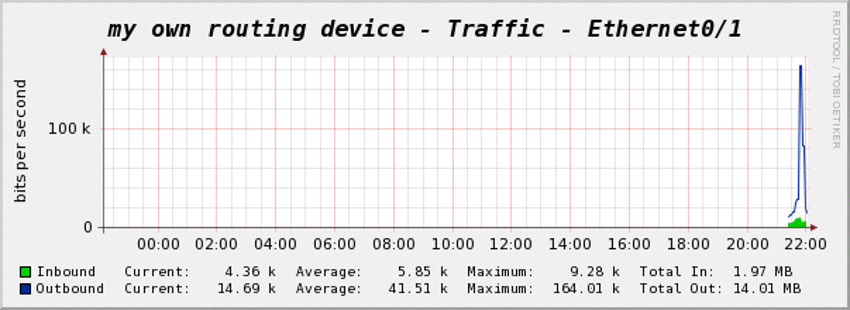
Zabbix
Zabbixは現在非常に人気のあるオープンソースの監視ツールの一つです。バックエンドはC言語で書かれています。WebインターフェースはPHP言語で書かれています。
2020年4月現在、最新安定版は4.4.1、LTS(長期サポート版)は4.0LTSです。
Zabbixはデータベースに収集した情報を格納するため、MySQLやPostgreSQLなどのリレーショナルデータベースと連携して動作します。
Zabbixでは、
- ICMP(ping)、SMTP、HTTPなどによるサービスの稼働状況の確認
- Zabbixエージェントを監視対象にインストールして、ホストのリソース監視(CPU、メモリ、ディスクなどの使用率)の監視
などの、複数の監視方法に対応しています。エージェントをインストールしなくても多数のホストやデバイスの監視に対応しているところが特徴的です。
Zabbixの詳細については、Appendixで取り上げますが、以下のようなダッシュボード機能を提供し、監視対象を一覧表示することができます。
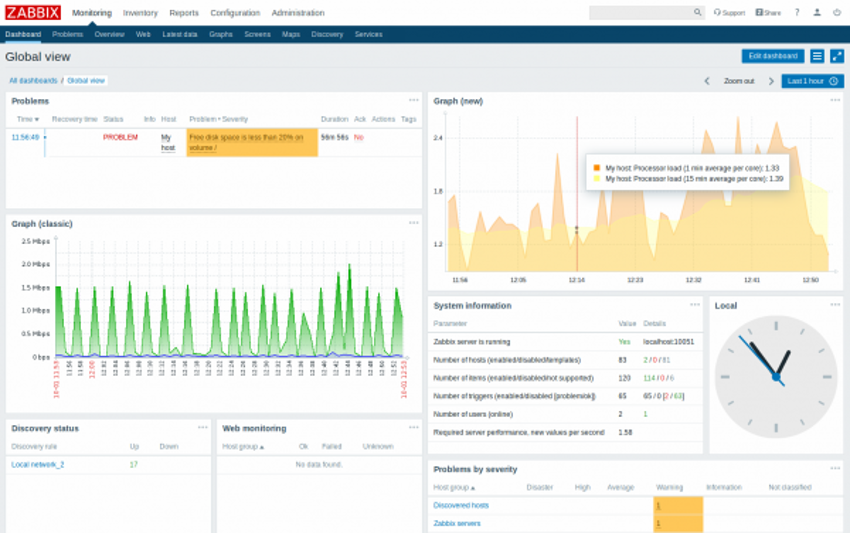
また、各ターゲットの詳細情報はウィジェットという四角形の領域に表示されます。例えば、以下はCPU使用率の監視結果を可視化したグラフです。
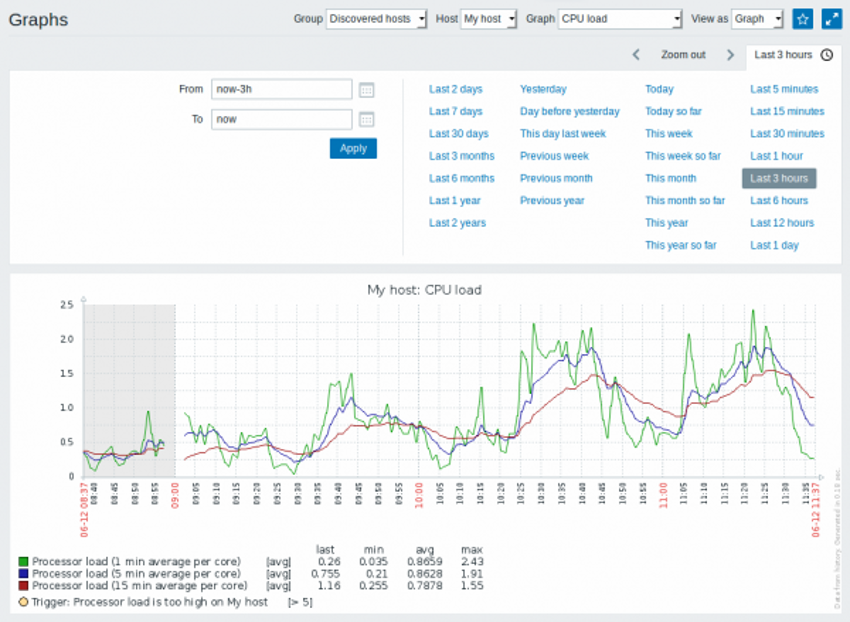
[1] Windows 10 Pro version 1903で確認
執筆者紹介
・太田 俊哉
・井上 博樹
このドキュメントは、LinuCレベル2の学習用の教材から抜粋して作成されたものです。教材全体は以下のPDFファイルをご覧ください。
LinuCレベル2学習教材