高可用システムの実現方式
この記事では高可用システムを実現するシステム構成の紹介や、評価するための方法などについて紹介します。(LinuCレベル2 主題:2.13.1)
このセクションでは、高可用システムを実現する方式について学びます。
システムに障害が発生すると、提供しているサービスが停止してしまい、社会的信用を失ったり、損害賠償を請求されたりするリスクがあります。
例えば、2016年3月にはANA(全日本空輸)の航空券予約・販売・搭乗手続きのシステムに障害が発生し、日本各地の空港で搭乗手続きや発券処理ができなくなってしまった事例などがあります。このケースでは、国内線のデータを格納しているデータベースサーバーを接続するイーサネットスイッチの故障が原因でした。
システム障害発生によるリスクを最小限にするために、バックアップや冗長化(構成要素の多重化や負荷分散)などの対策をあらかじめ講じておくことが重要です。
可用性に影響のある事象
システム障害が発生する原因には、以下のようなさまざまな要素があります。
- ハードウェアの老朽化・経年劣化、落下などの衝撃による物理障害(ハードウェア障害)
- システムの構成ミス、アプリケーションの設計ミスや不具合などの論理障害(ソフトウェア障害)
- ネットワークの障害
- オペレーションミスなどの人的要因
- 不正アクセス、コンピューターウィルス、DOS(悪意のある集中アクセス)などのセキュリティ攻撃
- 地震や水害、台風などの自然災害
また、メンテナンスのための停止も可用性に影響します。メンテナンスによる停止にも
- 定期的なバックアップなどのための計画的なサービス停止
- 過負荷によるサーバーダウンやディスク破損などに対応するための緊急的なサービス停止。
があります。
できるだけシステム停止時間を短くし、可用性を向上させるためには、サーバーや構成機器、アプリケーションの冗長構成などの工夫をします。ただし、無限にコストをかけるわけにもいかないので、さまざまな評価指標を用いて、コストとリスク低減のバランスを考えてシステム構成を工夫する必要があります。
SPoF, 回復性
システム停止を回避するには、その部分で障害が起きてしまうと、全システムが停止してしまう部分をなくす工夫が重要です。そして、システムの中で障害が発生してしまうとシステム全体が機能しなくなる要素は、「SPoF(Single Point of Failure:単一障害点)」と呼びます。
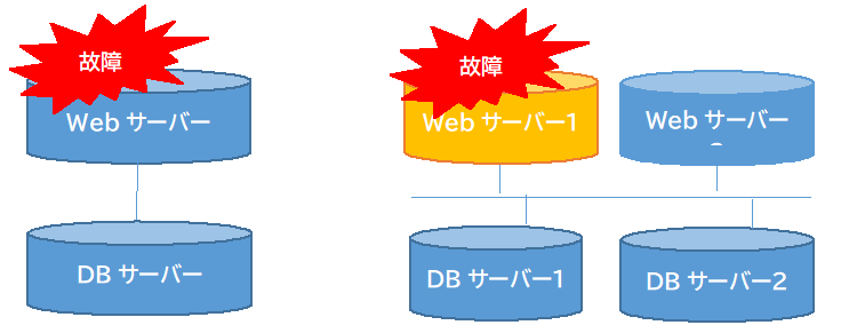
SPoF(単一障害点)のイメージ
また、システム障害が発生してしまった場合でもシステムを復旧させる時間を短縮するためにレプリケーション、つまり複数サーバー間でデータをリアルタイムにコピーしたり、同期したりする仕組みや複数のサーバーを同時に動かし、故障した機械から別の機械に切り替える、クラスタリングという手法が用いられることもあります。
許容される障害時間やコストを考慮し、クラスタリングやレプリケーションなどの工夫をして、システムの停止時間や復旧にかかる時間を限られた予算の中で以下に短縮できるか、ということが重要になります。
次の節ではシステムの稼働率や安定性を評価する指標について見ていきましょう。
可用性の評価方法
可用性を評価するためには以下のような指標がよく用いられます。
- 稼働率とSLA
- RTOとRPO
- MTBF(Mean Time Between Failure)
- MTTR(Mean Time to Repair)
稼働率とSLA
システムの稼働率を表すには、Availability(可用性)がよく用いられます。
Availabilityは、
(合意したサービス時間 – システム停止時間)/合意したサービス時間
をパーセント表示したものです。
クラウドサービスなどの契約には、サービス提供品質の指標として、Availabilityを用いてSLA(Service Level Agreement)を記述します。稼働率目標レベルを定義し、それを下回った場合に賠償請求ができるなどの項目を含むことがあります。
ISMS(情報セキュリティマネジメントシステム)では、情報の機密性・完全性・可用性を主要な3要素としています[1]。その中で可用性について定義をする際には、Availability(可用性)レベルを下表のようなクラスに分類し、目標レベルを定義します。
例えば、Availabilityレベルが99.9%だと、ダウンタイムは1年間に8時間45分(24時間x 365日 x 0.1%)となります。
| レベル | Availability(%) | 年間ダウンタイム(時間) | |
| レベル1 | 99.999 | 5分 | |
| レベル2 | 99.99 | 53分 | |
| レベル3 | 99.9 | 8.8時間 | |
| レベル4 | 99-99.5 | 44〜87時間 |
一般的な高可用化クラスタリングソフトウェアは、上記のうちレベル2の稼働率を実現するように設計されています。
MTBFとMTTR
また、システムの平均的な連続稼働時間をMTBF(Mean Time Between Failure、平均故障間隔)と呼びます。Failureはシステム障害のことなので、システム障害が発生するまでの平均的な時間、つまり連続稼働時間の平均値になります。MTBFは長いほど、システムが安定して稼働していると考えられます。 さらにシステムが停止してから再稼働するまでの時間はMTTR(Mean Time To Repair、平均修復時間)と呼ばれます。MTTRが少ないほど、システム障害が発生してから復旧するまでの時間を短く抑えられる、ということを意味します。
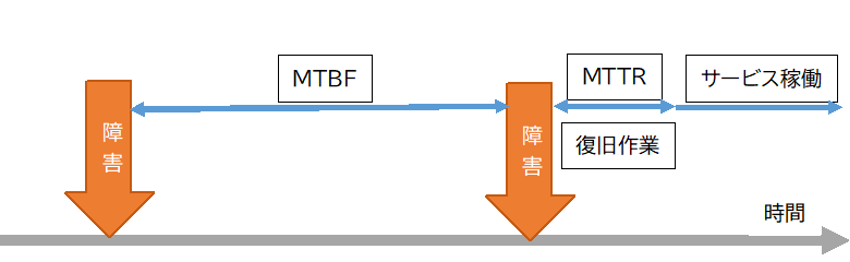
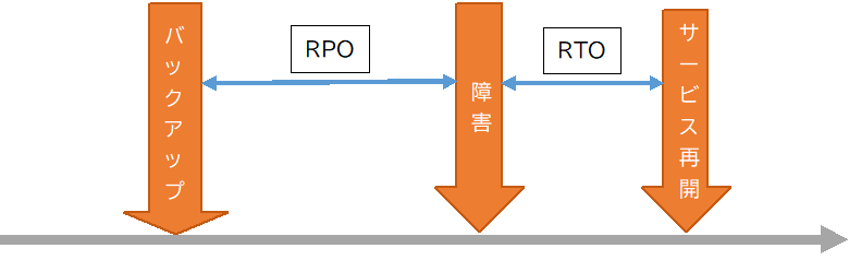
RTOとRPO
そして、高可用化システムを設計する際に用いられる指標には、RTO(目標復旧時間:Recovery Time Objective)とRPO(目標復旧時点: Recovery Point Objective)があります。
RPOはデータを復旧するバックアップデータの古さの目標です。どこまでデータを復元できるかの目標値です。これによりバックアップ手法や保存期間、バックアップ処理のタイミングなどを策定します。
RTOはシステムを再稼働するまでの時間です。障害が発生してから、データ復旧、機器の修理・換装などをして、サービスを再稼働するまでの目標値です。
それぞれを短くするとダウンタイムを短縮することができますが、コストは数値を小さくするほど増大します。
高可用性(HA: High Availability)を実現するシステム構成
可用性の高いシステムは、一般的に「高可用性のあるシステム」と呼ばれます。または略してHA(High Availability)構成と表記することもあります。
冗長化(HAクラスタ)
高可用性を実現するためには、サービスを提供しているマシンが停止してしまった際に、何らかの方法で、直ちにサービスを継続することが必要です。このためには、あるサービスを提供するシステムを多重化して、待機している予備マシンでサービスを引き継ぎます。引き継ぐ処理のことを「フェイルオーバー」と呼んでいます。こうすることで、ダウンタイムを極力少なくしてサービス提供が継続できるようになります。 こうした現用系(アクティブ)と待機系(スタンバイ)のノードから構成されるシステムは、HAクラスタ(高可用性クラスタ)と呼ばれています。
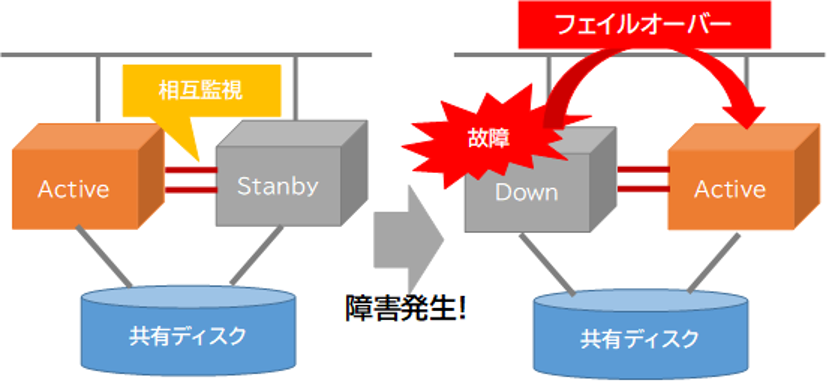
高可用性クラスタを構成するには、クラスタリングソフトウェアが使用されます。例えば、オープンソースで開発が進められているクラスタリングソフトウェアではPacemakerが有名です。Pacemakerはそれ以前から開発されてきたHeartBeatというソフトウェアのリソース管理機能だけを独立させたものです。
Pacemakerは単独ではHAクラスタを稼働させることはできません。Corosyncなどのクラスタを制御するソフトウェアと組み合わせて動作させます。
Pacemakerのエージェントプロセスは、各マシン上で常時起動し、アクティブ系なノードとスタンバイ系のノードで指定した間隔で死活監視をしています。
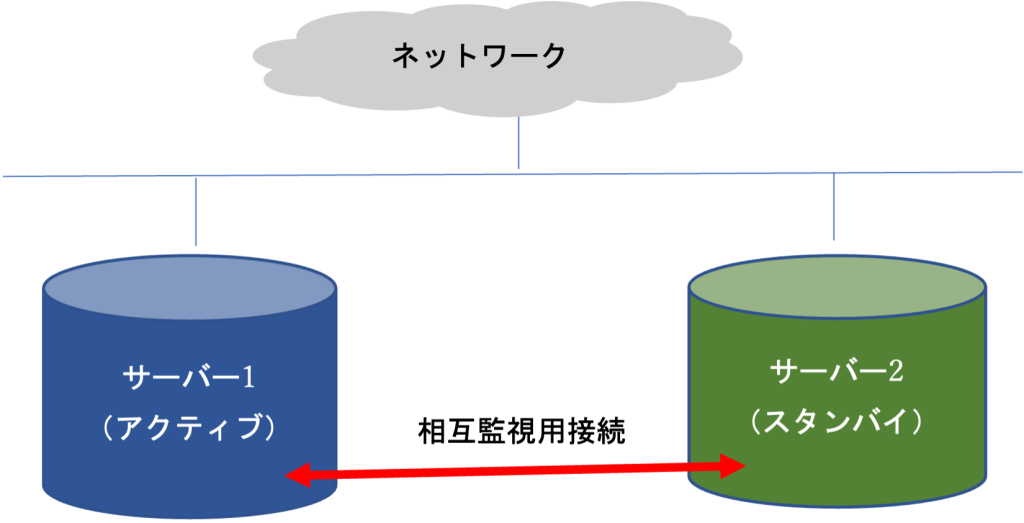
また、サービスの監視や制御をするためのプロセスはRA(リソースエージェント)と呼ばれます。RAは、サービスの起動、停止、監視などを行います。
RAには、Webサーバー(ApacheやNginx)、データベースサーバー(PostgreSQLやMySQL)、ネットワークインターフェース、ファイルシステムなどの監視に対応したものがあります。
そして、もしも障害を検出したら、待機系のマシンに処理を引き継ぎます。フェイルオーバーに失敗すると、両方のノードがアクティブになってしまいます。これをスプリットブレインと呼びますが、両方のシステムから共有ディスクにアクセスしてしまい、データの不整合や破損のリスクが発生します。
スプリットブレインを防止するためにSTONITH(Shoot The Other Node In The Headの頭文字)という仕組みが用いられます。STONITHは両方がアクティブにならないようにフェイルオーバー時に障害が起きた方のサーバーのOSを強制的に再起動したり停止したりする機能です。
ロードバランシング(負荷分散)
例えば、大学や企業のポータルサイトなどでWebアクセスが集中することでWebサーバーのメモリを使い果たしてしまい、応答時間が長くなったりWebページがホワイトアウトしたりしてしまう場合があります。
そこで、複数台のWebサーバー間で負荷を分散するために、
- DNSラウンドロビンを用いてランダムにアクセスを振り分ける
- ロードバランサを用いてサーバー負荷の監視を行い、できるだけ負荷の少ないサーバーノードにアクセスを振り分ける
などの工夫がされます。
物理的、地理的分散による可用性レベルの違い
同一拠点でハードウェアを冗長化するだけでは、自然災害などでデータセンターが機能しなくなった場合にシステム停止が発生してしまいます。
そこで、地理的に離れた複数拠点でロードバランシングしたり、データをレプリケーション(複製)したりしておく、などの工夫がサービス停止の回避に有効です。 前節のHAクラスタリングソフトウェアなどを用いると、複数拠点に配置したサーバー間でフェイルオーバーすることも可能となるでしょう。
執筆者紹介
・太田 俊哉
・井上 博樹
このドキュメントは、LinuCレベル2の学習用の教材から抜粋して作成されたものです。教材全体は以下のPDFファイルをご覧ください。
LinuCレベル2学習教材
[1] JIS Q 27000:2014